
AI is the hot commodity of the 2020s, and it is not slowing down anytime soon. AI is the fastest-growing and evolving phenomenon we have seen since the mass adoption of the internet, and I am not just saying that for effect. ChatGPT, the model that brought the potential of what this technology can do into the limelight, was released only a year and a half ago at the time of writing. Since then, we have gone from text to code to picture to video to multimodal models that can do it all. But there's a dirty secret behind these innovations: they are private property.
Yup. No sharing.
Even OpenAI, the creator of ChatGPT, transitioned from an open-source think tank to a closed, private company in 2019, right before their research became a commercially viable product. Sus, as the kids say. I guess they just forgot to change their name during the restructuring.
Fret not, though, reader! As is tradition, when big corporations spend billions on new technology that has major impacts on how we live, there is bound to be a rag-tag group of scrappy open-source research trying to put the power back in the hands of the common man. But sadly they don't have the time and capital these large companies do to spend resources on usability and documentation. It's impossible to match pace and polish when you're running on passion and energy drinks, and they're getting their daily dose of millions of venture capital dollars.
So let's take a bit and have an overview of the current open-source ecosystem and terms you need to know to navigate it.
Part 1: Where do I even find models?
Quick aside: While we will focus on LLM (Large Language Models), similar to ChatGPT and Gemini, most information will be applicable to other types of models.
Okay. I am interested in joining the revolution and running my very own AI model on my computer. Where do I start?
There's really only one answer for this: Hugging Face.
Hugging Face is an AI research and deployment company, recognized for its comprehensive website that serves as a hub for machine learning and natural language processing technologies. The website offers a vast repository of open-source pre-trained models, datasets, and tools, facilitating collaboration within the AI community.
Though the cyberpunk Mr. Robot-esq side of me is a bit saddened that even in open-source world we are consalidated, it makes it extremely convenient to look for new models to explore.
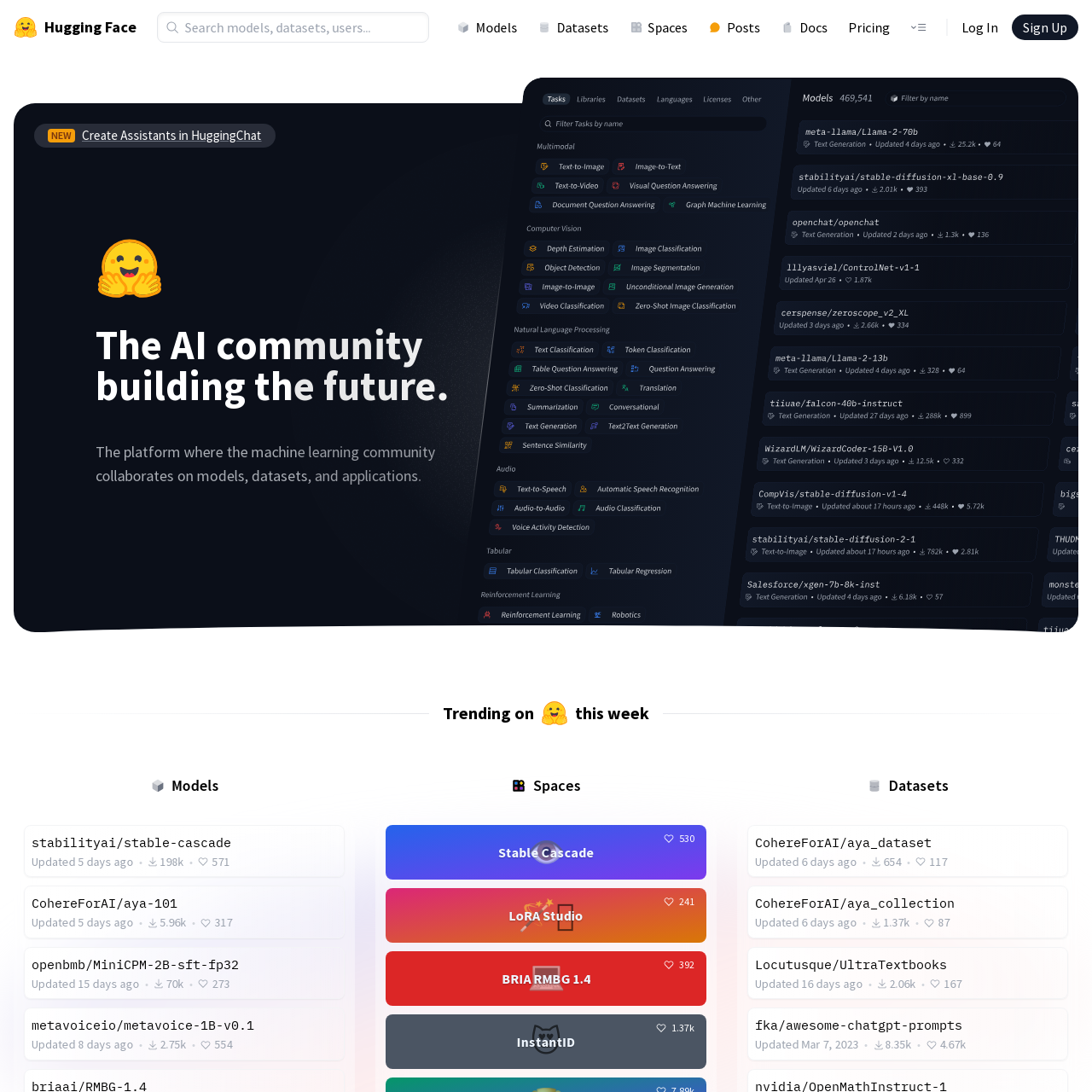
Immediately upon reaching the home screen, you will be greeted with multiple options for navigation. A few notable ones I will mention:
- Models - This is where all pre-trained off-the-shelf models will be. If you are just starting in AI, this is the only section you will likely use. It contains the models to download, as well as documentation on what kind of model they are and how to use it (more on that later).
- Datasets - SUPER awesome tab if you decide you like this stuff and decide to get further into making your own models. Contains curated sets of training data. Want to make a model that's really really good at coding? There's a dataset for that. What about one that speaks Somali? Contains all the knots needed to hoist the sail in a 30-foot sailboat? It's probably in this section.
- Spaces - A collection of community-made ML-based apps, most of which are hosted directly on Hugging Face. Before paying for an AI app on a website, check here first.
- Docs - A huge amount of detailed documentation on concepts used in AI in general and Hugging Face in particular. Note that this section assumes some baseline knowledge and doesn't do the best job of taking people from zero to hero. However, if you can get comfortable with the terms and concepts - it is awesome.
Lastly, I will mention there there is a Pricing section. All the features you need are likely free, so don't worry about affordability. Let's head over to the Models section and use the filter on the left to look for only Text Generation under the Natural Language Processing section. This will filter only to models that deal with language (NLP as they are commonly called) and that generate text as an output. After filtering, find meta-llama/Llama-2-7b-chat-hf.
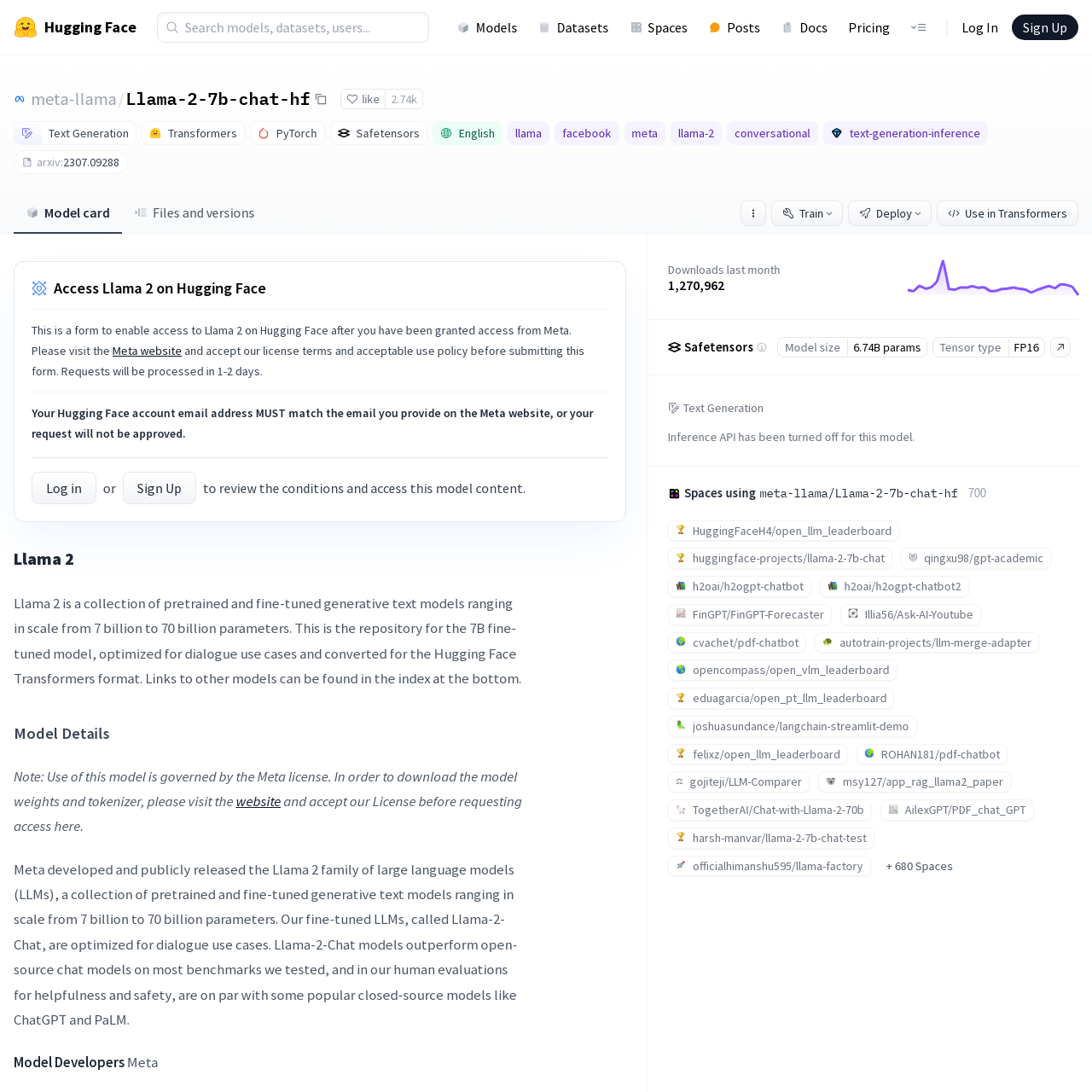
Let's summarize a few things on this page to understand what is happening.
First, the model's name is Llama 2 and it is an open-source LLM (Large Language Model) made and maintained by Meta (Facebook). Meta has been one of the few large companies to make sizeable contributions to the open-source community in AI in recent years, and you will commonly see Llama used as a baseline model for open-source enthusiasts (it even boasts the largest subreddit for an open-source model).
On this page, we can also see one of the most important motifs used in LLM-land, the parameter size. Parameter size can be used as a rough analog to performance, and also computational requirements to run.
Consider parameters as the number of small logic gates your input traverses, equating to the 'thought process' it undergoes before producing an output. While this analogy isn't perfect, it is a useful metaphor for our discussion.
Parameters are actually representing how many weights and baises are in the modle. Input does not pass through all of them. Weights and baises determine which neruons either turn on, or don't, inside the model. Unless you are building your own model a cursory understanding is more than fine.
That's all fine and dandy, but we want to run the model now. You may be tempted to run over to the Files and Versions tab and be exasperated to see there is no launch_modle.exe file, only a bunch of weird file types you've never heard of. Fear not, there is an easier way,
Part 2: Introducing Ollama, unaffiliated.
Weirdly, finding the model you want to use is often the hard part thanks to your new best friend, Ollama.
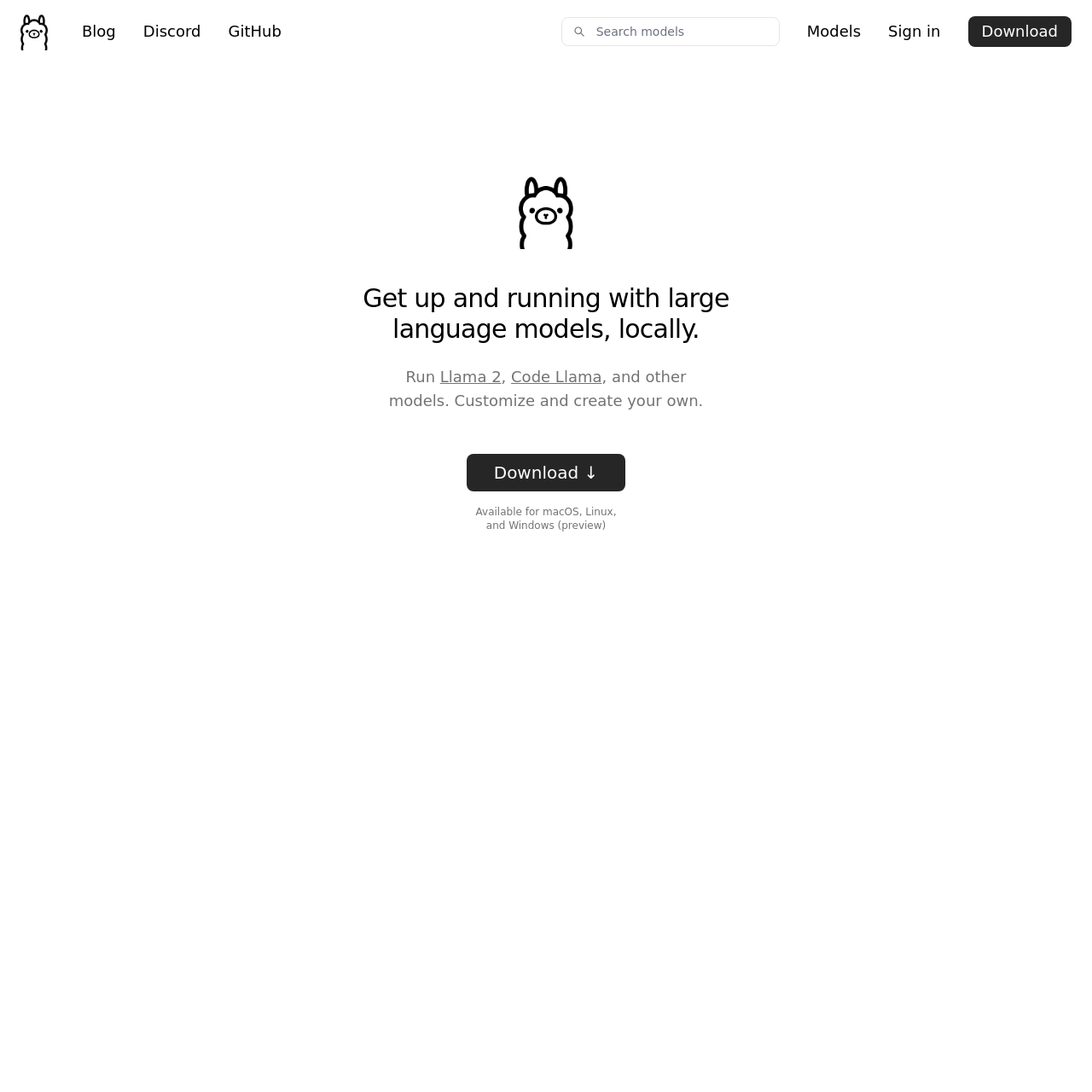
Ollama is an open-source project that makes it stupidly easy to run an LLM locally. It even has its own model repository that you can install directly from the app; no downloading from Hugging Face is necessary for most popular models. However, it still sources models from Hugging Face on the backend. Additionally, you can add models from Hugging Face that it has not added yet to its repository. Downloading is also simple.
Linux:
curl -fsSL https://ollama.com/install.sh | shMacOS/Windows:
Download the respect executable from their downloads page: https://ollama.com/download
I would recommend using Linux (or Windows Subsystem for Linux) if possible; I have found it to be more stable. After installation, simply run the command:
ollama run llama2
This will download the model to your local machine (~3.8GBs) and execute it. As the model is only 7B in size, it should be able to run on most modern hardware with a decent amount of RAM (16GB should be fine).
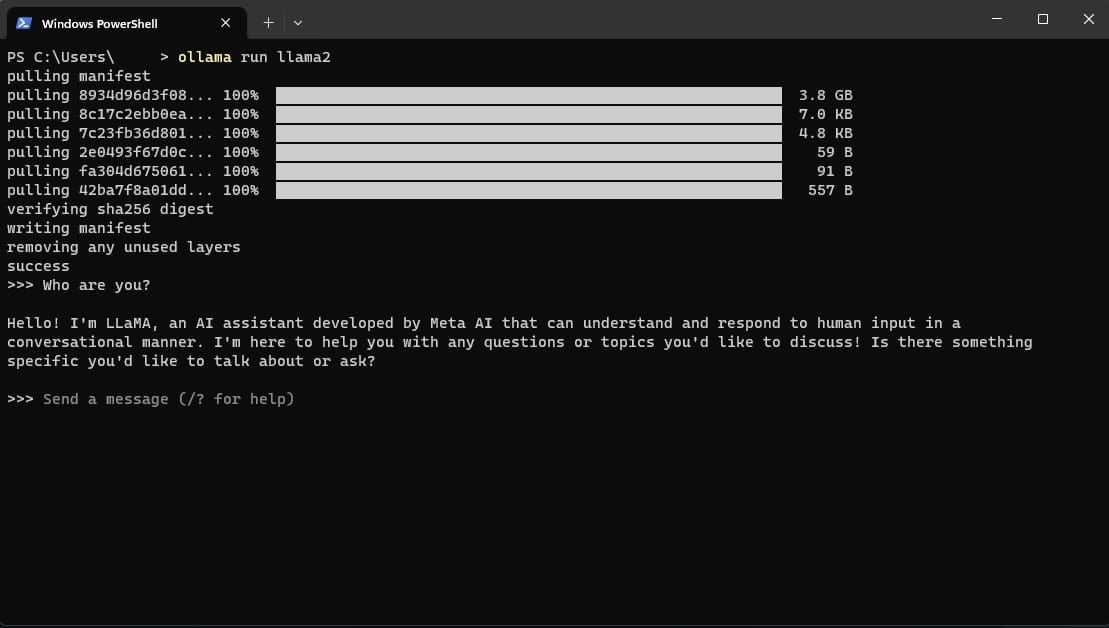
You did it! Now you are beholden to no company, and all your interactions with your LLM stay on your machine only. You can even name it something weird, like Keith.
Part 3: Now what?
Explore the model library on Ollama.
There are many models on the Ollama library for you to check out. Why not try LLaVa, a multimodal model that can produce and understand images and text? Simply run:
ollama run llava
The sky is the limit. Well, also your computer's "fire catching" limit. Whichever comes first.
Hate looking at the terminal? You can fix that.
If you're anything akin to a human, you probably don't enjoy looking straight at a terminal all day (not sorry). Luckily, there are people who agree and did something about so you don't have to. Check out open-webui, a framework with a pretty ChatGPT-like frontend that hooks up directly to your Ollama instance. It also had integrations to do things like web search, connect to multiple models, use multi-modal models, and much more.
Most models are still censored.
WHAT THE HECK?? I ASKED THE MODEL TO TELL ME SOMETHING BAD AND IT GOT MAD AT ME 😠😤😠
Yup. Most models released are censored, so even offline, they will not do things their creators do not want to be done. Fear not, my morally ambiguous compatriot, there are ways around this. The first option is prompt injection, which is a fancy way of saying you must sweet-talk the AI. With enough charisma, even the best AI can be bypassed!
Though this deserves another blog post in itself.
Alternatively, you can choose to use models that are already uncensored. Dolphin made by Eric Hartford, is the current big dog in uncensored models. It features multiple different model types to choose from, all free and uncensored. Just don't do anything weird or violent, please. If you do, we're not friends anymore. Just think about that.